01丨明确你的前端学习路线与方法
第一个方法:建立知识架构
如果让我做一个划分,前端的知识在总体上分成基础部分和实践部分,基础部分包含了 JavaScript 语言(模块一)、CSS 和 HTML(模块二)以及 浏览器的实现原理和 API(模块三),这三个模块涵盖了一个前端工程师所需要掌握的全部知识。
学完这三个部分,你再结合基本的编程能力,就可以应对基本的前端开发工作了。实践部分(模块四)重点会介绍我在工作过程中遇到的问题和解决方案,希望这块内容能够帮助你和你的前端团队找到可能的发展方向和着力点。
JavaScript
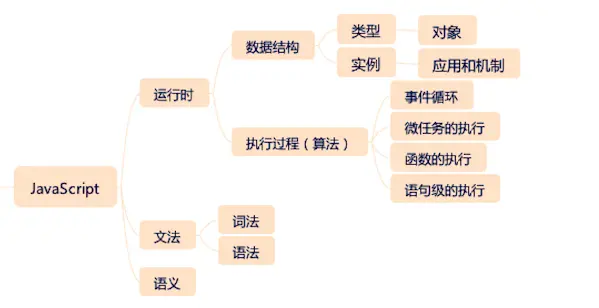
JavaScript 的类型系统就是它的 7 种基本类型和 7 种语言类型,实例就是它的内置对象部分
undefined、null、object、boolean、string、number、symbolList 和 Record、Set、Completion Record、Reference、Property Descriptor、Lexical Environment、Environment Record、Data Block
HTML 和 CSS
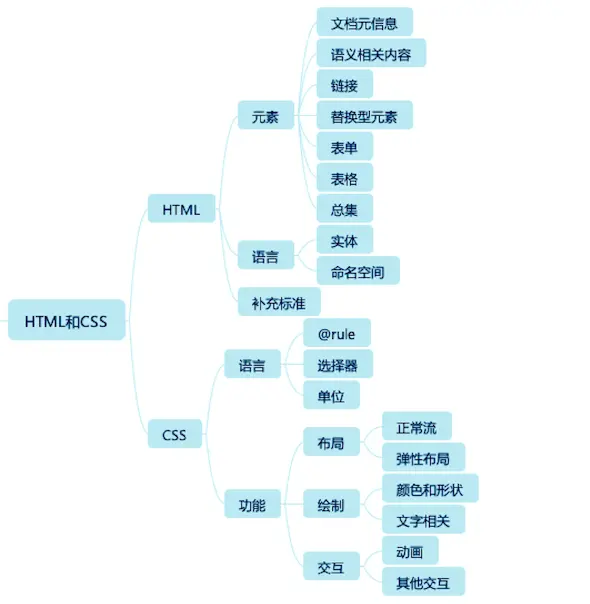
文档元信息:通常是出现在 head 标签中的元素,包含了描述文档自身的一些信息;
语义相关:扩展了纯文本,表达文章结构、不同语言要素的标签;
链接:提供到文档内和文档外的链接;
替换型标签:引入声音、图片、视频等外部元素替换自身的一类标签;
表单:用于填写和提交信息的一类标签;
表格:表头、表尾、单元格等表格的结构。
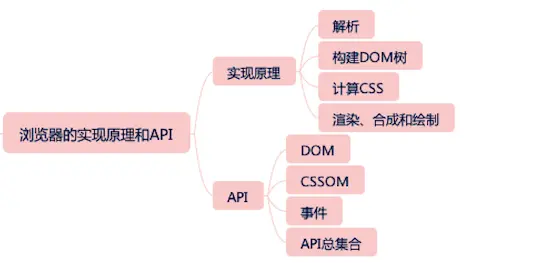
浏览器的实现原理和 API
前端工程实践

第二个方法:追本溯源
还有一些知识,涉及的概念本身经历了各种变迁,变得非常复杂和有争议性,比如 MVC,从 1979 年至今,概念变化非常大,MVC 的定义几乎已经成了一段公案,我曾经截取了 MVC 原始论文、MVP 原始论文、微软 MSDN、Apple 开发者文档,这些内容里面,MVC 画的图、箭头和解释都完全不同。
这种时候,就是我们做一些考古工作的时候了。追本溯源,其实就是关注技术提出的背景,关注原始的论文或者文章,关注作者说的话。
操作起来也非常简单:翻翻资料(一般 wiki 上就有)找找历史上的文章和人物,再顺藤摸瓜翻出来历史资料就可以了,如果翻出来的是历史人物(幸亏互联网的历史不算悠久),你也可以试着发封邮件问问。
这个过程,可以帮助我们理解一些看上去不合理的东西,有时候还可以收获一些趣闻,比如 JavaScript 之父 Brendan Eich 曾经在 Wikipedia 的讨论页上解释 JavaScript 最初想设计一个带有 prototype 的 scheme,结果受到管理层命令把它弄成像 Java 的样子(如果你再挖的深一点,甚至能找到他对某位“尖头老板”的吐槽)。
根据这么一句话,我们再去看看 scheme,看看 Java,再看看一些别的基于原型的语言,我们就可以理解为什么 JavaScript 是现在这个样子了:函数是一等公民,却提供了 new this instanceof 等特性,甚至抄来了 Java 的 getYear 这样的 Bug(从相关文档中能看出 @Deprecated public int getYear() { return normalize().getYear() - 1900; } 用这个方法获取年份时是从1900年开始计算的)。